Back in December, GC English student Sarah Ruth Jacobs posted about the possibility of losing software that might be of interest to English students:
There are 5 installations of a text mining software that can be used for qualitative and quantitative textual analysis called QDA Miner with WordStat and Simstat in room 5487 at the Grad Center. The IT person at the meeting said that it has only been used ONCE, and so if we want to keep it we need to use it.
Having absolutely zero experience with text mining software, I decided to ask the person responsible for using it ONCE if the rest of us folk were missing out on anything.
Enter the English department’s very own digital guru Amanda Licastro, who used text mining tools for a paper in Spring 2011 in order to analyze 36 prefaces published between 1600 to 1800. Drawing from Franco Moretti’s 2009 Style, Inc. Reflections on Seven Thousand Titles (British Novels, 1740–1850), Amanda used these tools to identify frequent keywords in her sample selection. By analyzing these keywords and their contexts — with both new tools and traditional methods — she was able to make several suggestions about the role of the preface in the 18th century.
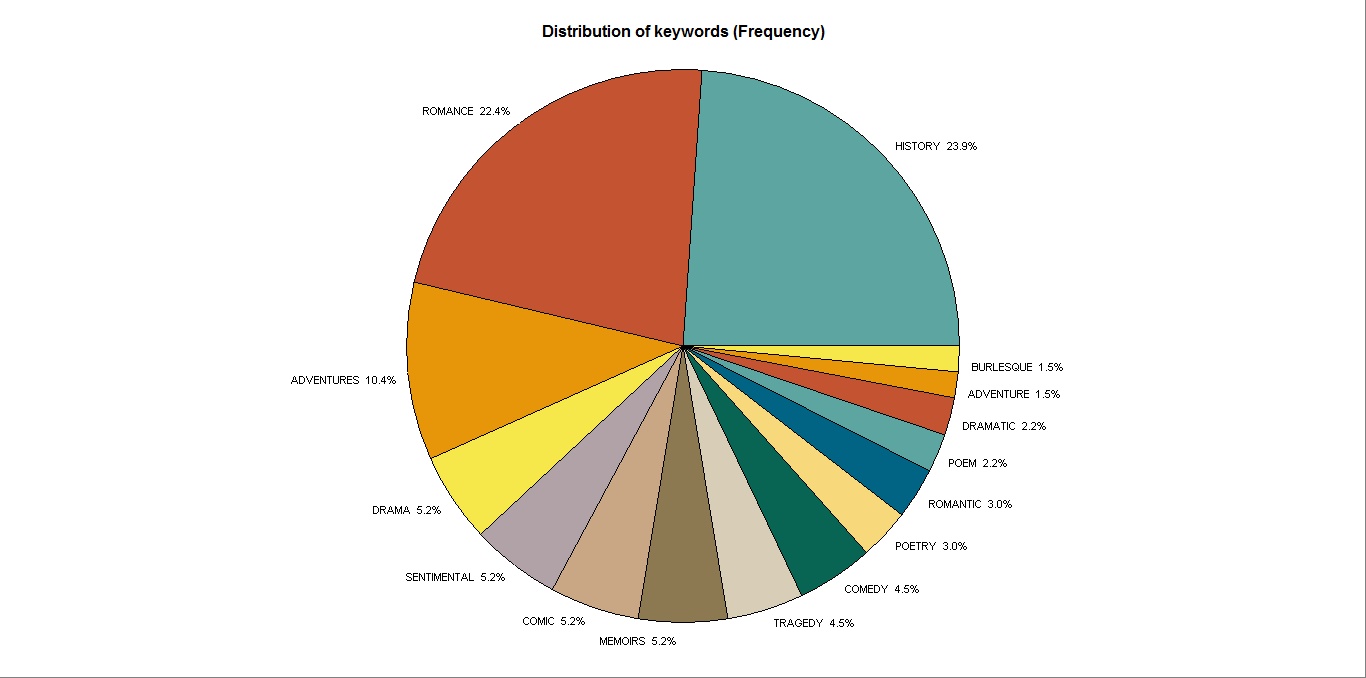
Piechart from Amanda Licastro’s paper “The Rise of the Preface.”
But the other interesting thing about her paper is her comparison of two different types of text mining tools. Amanda experimented with both QDA Miner with Wordstat 6.1 (which clocks in around $4000 for commercial use) and also a similar (though free and open source) tool, Intelligent Archive. Though Intelligent Archive did not come with all the bells and whistles of QDA Miner (such as automatically outputting charts like the one shown above), Amanda did recommend the open source tool as a respectable alternative. Just remember, regardless of which tool one uses, to “always clean up your data!”
I thank Amanda for her full comparison here:
There are remarkable differences between the two programs, and as part of this experiment I would like to point to several that are significant in terms of textual analysis. The Intelligent Archive allows the user to filter out common words such as prepositions and articles, WordStat does not. It also allows you to search coded text if you have a text uploaded in the Textual Coding Initiative (TEI) format. As of May 2011, TCP has released thousands of TEI encoded eighteenth century texts, but they are still not publicly available to download. The QDA Miner solves this problem by allowing you to code text easily within the program. The user can encode any amount of text and designate it as a part of a user generated category. The coded text can overlap and be coded as more than one category. The coded text is searchable, and the user can perform content and statistical analysis using the data from one category of coded text, or can compare multiple sets of data. For instance, you can do a word frequency on one set of coded text and the results will show that word in the context of a sentence or paragraph, determined by the user before the search. The user can then eliminate uses of the word that do not fit the experiment before opening the list in WordStat to create graphs or charts that display the results. This gives the user more control over their results by adding a process that at this time still necessitates human intervention, because the program cannot yet identify the meaning of a word by the context in which it is used. It would be impossible to create valid codes and properly narrow the results without a strong understanding of the original material. In other words, it is at this point when traditional literary scholarship is necessary.
{kind=link}