
Databases For Dummies Smart People Who Are Scared of Databases
Databases are one of those things that come in conversations about digital technologies all the time and in infinitely many contexts. For many folks, the mere mention of the word conjures anxieties about a complex and highly technical system running on room-sized servers staffed by a group of bespectacled people with clipboards and lab coats, or an IT goblin stashed away in a basement (see also: Richmond from The IT Crowd).
Fear not! Databases are much easier to understand than you probably think, and knowing your way around databases is an invaluable skill for anyone getting into web development, application development, GIS, statistics, archives management, or just about anything else that deals with large amounts of information.

Database servers aren’t just for creepy goths holed up in a sub-basement.
What is a Database? By Example…
At the most basic level, a database is a way of storing and organizing information. Think of an old school library as a database. Items such as books, magazines, videos, and microfilm all represent various types of data stored within this “database.” Typically, libraries organize items using the Dewey decimal system, which uses fields of knowledge to classify items into hierarchies. The card catalog or computer search system serve as indexes allowing visitors to look items up by author’s last name or subject categories (or other indices in the case of the computer system). The card catalog can then point visitors to the place within the library where the desired information is stored. In this way, the library functions as a complete database system.
Another example of a database in action is a WordPress blog like the one running this site. With a blog, each page and post is stored as an entry in a database, sort of like individual books in a library. Each of these entries also contains “metadata”, or descriptive information, about things like the entry date, author, and whether it’s a public or private post. Elsewhere in the database are entries about things like the title of the blog, contents of the menus, information about the theme and plugins being used, the blog’s users, and records for every comment left by visitors. You can think about the organization of these various categories of information as the WordPress equivalent of the Dewey Decimal System. This is the database structure. When you load the main blog page and it displays the most recent posts, you are seeing the results of a database request where the “posts” section of the database looks at the date associated with each blog post, and returns the posts with the most recent dates. WordPress then handles formatting the information associated with each post based on the theme, which itself requires looking up more information from the database about which theme the blog administrator selected.
Why Use Databases?
The easiest answer to the question of why you might use a database is, if you have dynamic data (information that can change over time) or sets of data that need to be processed or queried (sorted, computed, searched, etc.), then you should be using a database. Spreadsheets are fantastic for working with dozens up to thousands of datapoints. But to use that information in dynamic ways, such as on a website, in a computer program, or to produce complex data visualizations, one should probably make use of databases that can be queried and manipulated, and can store information with complex, multi-dimensional relationships between data points.
Different Types of Databases
The examples above are only two very basic, heavily abstracted, examples of databases. Databases can be used for all sorts of applications. Depending on the type of information is being stored, and what types of operations will happen on that data, there are several different types of databases systems one can use in computing environments. For this brief introduction, I am going to focus on relational databases. Other types include document-oriented databases, graph databases, hierarchical and network databases, and object-oriented databases. There is some overlap between these database models, and really the differences between them and when to use each could easily fill a semester long course on databases. But since relational databases remain the most common type of database encountered, arguably the most powerful (since one can implement other types of database models within a relational database), and are by far the simplest to learn, they will be the focus of the remainder of this post.
Overview of Relational Databases
At its most basic level, relational database systems store information in discrete databases, where typically each database is project specific. A single database system can have many databases, each with its own users and access permissions. Within a database there are multiple tables, each containing rows and columns, sort of like a spreadsheet. Each table stores sets of related data, for example, information about a collection of books. Within a table, each row represents an entry (e.g., a unique book), while columns, also called fields, represent the categories of information that will be stored for each entry (e.g., book title, year published, etc.). Information about a different set of data, which may or may not be directly related to the first table, can be stored in a second table, for example, a table of authors containing columns such as first and last names.
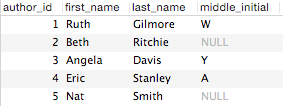
An example “authors” table. “NULL” means no data was entered for a field in a given row.
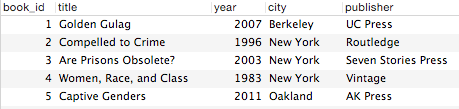
An example of a “books” table
One of the defining characteristics of relational databases is that the structure of database tables needs to be explicitly defined. This means that every column/field must be defined in terms of metadata characteristics like a data types (number, date, text, etc.) and whether or not its values need to be unique or if multiple rows can contain the same value. Using the example of books from above, fields might include (data type in parenthesis): the book’s title (text), year published (date, number, or text), publisher (text), and city of publication (text). All tables also have a unique identifier associated with each row, which is typically a whole counting number, in the example it’s the book_id. The image below shows these fields along with their associated data types. In MySQL, the database used for this example, INT stands for integers (positive or negative whole numbers), VARCHAR stands for text of indeterminate length.
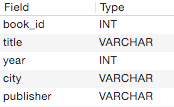
The structure of the “Books” table. Each item is a “field” or column in the table
The last defining characteristic of relational databases covered here is the relationships between tables. Relationships between different tables can be established in several ways, but the most basic is a reference, called a foreign key, which that is shared between two tables. For the book example, I want to store the relationships between authors and the books they’ve written. For this, I create a new table where each row represents a relationship between authors and their books. The image below illustrates the relationship between the three tables, books, authors, and book_authors, where the author_id and book_id form the link between the tables.

“book_authors” links books to authors in many-to-many relationships. Click to enlarge.
Importantly, for this data set, this relationship can be 1) one-to-one, meaning a single author wrote a book; 2) many-to-one, meaning multiple authors share credit for a single book; and/or 3) one-to-many, meaning one author has written multiple books. The data for the book_authors table connects one or more rows from the authors table to one or more rows in the books table (e.g., the book with book_id “1” was written by the author with author_id “1”; author “3” wrote both books “3” and “4”; book “5” was written by authors “4” and “5”):
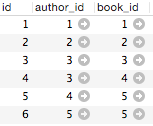
The table “books_authors” contains the IDs of rows from the authors and books tables
When retrieving data from the database, it’s possible to “join” tables based on these relationships. So from the example, I can join the authors table with the book_authors table on the author_id field, while also joining the book_authors table with the books table on the book_id field, returning a complete list of all of the authors and books:
The “joined” book and author tables based on the “book_author” relationship table. Click to enlarge.
For the record, the SQL for the example database used in this post is included at the bottom of this post.
Data Storage and Access
Databases are typically designed to act as “black box” information storage systems, meaning that the user has access to tools and commands to access and manipulate the data without ever having to worry about how the database is actually storing it on the computer or server. There are plenty of technical details that distinguish different database systems from each other, but the beginning user should only have to worry about what tools are available to interact with the data and how the data is accessed from the database. For this reason, the database is a “black box” where basic users don’t need to know how the sausage is made, only how to cook it and eat it.
Interacting with a database requires a “connection” to the database server. The term “server” loosely means any computer running the database software, where the data is stored. This could be your personal computer, a web server, or a “cloud” server with multiple nodes connected via the internet. Starting out, you will probably rely on a local server running on your personal computer. If you build a web app, and are getting ready to “deploy” it on the web, you would copy your testing database from your local computer over to your web host’s servers. To connect to the database server, you use a database “client”—a standalone program, web interface, or programming language capable of communicating with the server—to establish a “connection” to the server and tell it, “get ready to receive commands.”
Once the connection to the server is established, the “client” communicates with the database server using commands and queries to do things like create new tables, add data, and lookup subsets of data. The most common relational database systems, such as MySQL, Microsoft SQL Server, and Postgres SQL, use commands based on SQL, or Structured Query Language, and pronounced “sequel.” For beginners, the easiest way to interact with the database is through the use of graphical tools, which make it so you don’t actually need to learn SQL to interact with your data. Especially if you’re just trying to view and maybe edit data in an existing database (e.g., check under the hood of your WordPress blog or manipulate your ArcGIS data), these graphical tools are invaluable. Most web hosts provide access to a MySQL server and pre-install a tool called phpMyAdmin that allows users to interact with the MySQL database through a relatively straight-forward web-based interface. If you try out WAMP/MAMP/LAMP (see the Conclusion, below), phpMyAdmin is included and linked from the homepage after you start the servers, so you can jump right in and start creating databases. There are also standalone applications, such as MySQL Workbench, SQuirreL, HeidiSQL, or Sequel Pro (used for the screenshots used in this post) that are even easier to work with than phpMyAdmin and allow you to import and export data using copy-paste or from existing .csv or .xls files.

The Sequel Pro database client on OS X. Click to enlarge.
Many database systems also provide libraries and APIs, or Application Programming Interfaces, that allow users to interact with the database in various programming languages, such as Python, PHP, C, Java, or through HTTP, the “language” of the web. When using a library or API, you use functions within the programming language to connect to the database server, store or retrieve data, and ultimately, work with the data and output it to end-users of your program or viewers of your website. If you are using a SQL database system, most programming languages let you send explicit SQL commands to the database so that you can perform complex queries and computations on the database server, and only worry about the retrieved data in your program. Importantly, the database server does not have to be running on the same computer as the program or script you develop. So you can have an application running on a mobile device communicate with a remote server through the internet, or you could use a local database to store data directly on the device itself.
Conclusion
Hopefully this relatively brief introduction provides a general sense of what a database is and why you might use one. The examples provided are very basic and don’t really give a sense of the different use cases, particularly in the world of web and mobile apps, where they’re used to store everything from user information to social networks to content (think status updates, images, videos, etc.). Relational databases are not at the forefront of hip buzz-word techspeak, but for the beginner, they are an important building block to information storage, and in many cases, remain the most straightforward, reliable, and high-performance way to begin developing an application. So as you look for next steps, I implore you to find a hands-on tutorial based on the most widely used open source database platform, MySQL. If you’re on a Mac or Linux computer, it’s already installed and requires no special tweaks to get going. On Windows (as well as Macs and Linux), there are development packages such as WAMP (MAMP on Macs, LAMP on Linux) or AMPPS, that require little more than a file download and a couple mouse clicks to get a MySQL test server running on your computer, along with the phpMySQL tool to interact with it.
As a final note, it’s worth mentioning NoSQL databases such as MongoDB, Cassandra, OrientDB, Hadoop HBase, and XML databases, because of their growing popularity, particularly in scalable and real-time web applications and cloud/distributed computing environments. These database categories and systems function differently from relational databases in that the database structure and data models are fundamentally different, not based on tabular structures (tables), they employ different types of relationships between data items, and often store information in discrete documents for each data item, where relational databases create files based on tables (or subsets thereof). Because there are quite a few different types of NoSQL databases, each with different strengths and weaknesses depending on the particular application, I would suggest avoiding them altogether until you become comfortable interacting with relational databases using a programming language. And even then, their strengths only begin to shine when you’re dealing with massive datasets, highly unstructured data, parallel computing, real-time performance, or require the use of scalable cloud servers.
Example SQL Database Used in this Post
The code to create the tables and insert sample data:
# Dump of table authors
# ------------------------------------------------------------
CREATE TABLE `authors` (
`author_id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`first_name` varchar(255) NOT NULL DEFAULT '',
`last_name` varchar(255) NOT NULL DEFAULT '',
`middle_initial` varchar(10) DEFAULT NULL,
PRIMARY KEY (`author_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `authors` (`author_id`, `first_name`, `last_name`, `middle_initial`)
VALUES
(1,'Ruth','Gilmore','W'),
(2,'Beth','Ritchie',NULL),
(3,'Angela','Davis','Y'),
(4,'Eric','Stanley','A'),
(5,'Nat','Smith',NULL);
# Dump of table book_authors
# ------------------------------------------------------------
CREATE TABLE `book_authors` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`author_id` int(11) unsigned NOT NULL,
`book_id` int(11) unsigned NOT NULL,
PRIMARY KEY (`id`),
KEY `author_id` (`author_id`),
KEY `book_id` (`book_id`),
CONSTRAINT `book_authors_ibfk_1` FOREIGN KEY (`author_id`) REFERENCES `authors` (`author_id`),
CONSTRAINT `book_authors_ibfk_2` FOREIGN KEY (`book_id`) REFERENCES `books` (`book_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `book_authors` (`id`, `author_id`, `book_id`)
VALUES
(1,1,1),
(2,2,2),
(3,3,3),
(4,3,4),
(5,4,5),
(6,5,5);
# Dump of table books
# ------------------------------------------------------------
CREATE TABLE `books` (
`book_id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(255) NOT NULL DEFAULT '',
`year` int(11) unsigned NOT NULL,
`city` varchar(255) DEFAULT NULL,
`publisher` varchar(255) DEFAULT NULL,
PRIMARY KEY (`book_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `books` (`book_id`, `title`, `year`, `city`, `publisher`)
VALUES
(1,'Golden Gulag',2007,'Berkeley','UC Press'),
(2,'Compelled to Crime',1996,'New York','Routledge'),
(3,'Are Prisons Obsolete?',2003,'New York','Seven Stories Press'),
(4,'Women, Race, and Class',1983,'New York','Vintage'),
(5,'Captive Genders',2011,'Oakland','AK Press');And the query to retrieve the list of books joined with their authors:
select
id, book_authors.author_id, book_authors.book_id,
first_name, middle_initial, last_name,
title, year, city, publisher
from book_authors
inner join authors on book_authors.`author_id`=authors.`author_id`
inner join books on book_authors.`book_id`=books.`book_id`



{kind=link}