
Working with HathiTrust Data
This post is Part 1 of a three-part series providing an introduction to the HathiTrust’s Digital Library and text analysis tools. In Part 1, below, I provide a brief introduction to text analysis and show how to create collections in the HathiTrust Digital Library. In Part 2, I discuss how the HathiTrust Research Center’s inPho Topic Model Explorer allows us to perform a particular kind of text analysis operation. Finally in Part 3, I discuss ways of accessing and analyzing the HathiTrust’s data at scale.
All three posts in this series are written to supplement these slides on Working with HathiTrust Data, by providing a narrative overview. I have organized these posts following the modules from the slides to allow the reader to move between the two and focus on the sections that are most interesting to them. This post is aligned with Modules 1 and 2 in the slides.
The HathiTrust Digital Library preserves and provides access to over 17 million books spanning more than four centuries. It was created in 2008 by digitizing and bringing together the physical collections of a number of distinguished academic research libraries. Today, The HathiTrust Digital Library comprises over 120 partner institutions who continue to contribute to its collection. Alongside the Digital Library, the HathiTrust Research Center provides tools that facilitate text analysis on its vast corpus.
Introduction to Text Analysis
Text analysis refers to a diverse array of computational methods to analyze collections of textual data and discern patterns of information. Text analysis can be used for a variety of purposes, such as conducting exploratory research to evaluate general trends and identify outliers. It can also be used to create tools, like spam filters that get rid of unwanted email or build Twitter bots based on certain themes and personalities.
Text analysis works by transforming a given text or a collection of texts into quantifiable units. For example, a text analysis approach to literary studies might begin by turning a lengthy novel with many chapters and an intricate plot into a unique collection of words. Once a text has been transformed into data, a variety of statistical methods are applied to count and tally the data, the results of which are then used to create and test hypotheses. Text analysis can be used for a variety of research projects, such as comparing authorial voice, determining major themes in large bodies of literature, and studying differences in the usage of language. These are just some of the possibilities, among many other research questions that emerge from the quantitative study of culture and language.
Given that the HathiTrust is a massive collection of books, it is especially suitable for text analysis projects. The HathiTrust provides both, a richly structured dataset, as well as a set of tools that facilitates text analysis projects.
Gathering Textual Data Using the HathiTrust Interface
Gathering textual data is an essential step in the text analysis process. To create a collection of texts on HathiTrust, you need to first log in to the HathiTrust Digital Library using your institutional credentials. This will allow you to store and share your collections.

Fig 1: HathiTrust Home Page and Log In Screen
The next step is to use the HathiTrust Digital Library’s search interface to find the works that you would like to include in your collection.
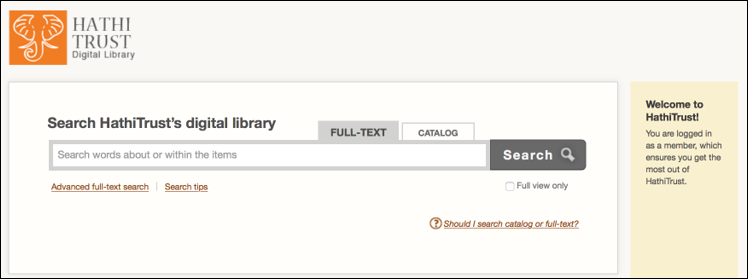
Fig 2: HathiTrust Search Interface
Once you have found the text(s) that you would like to add to your collection, you can then select them and either create a new collection or add to an existing collection.
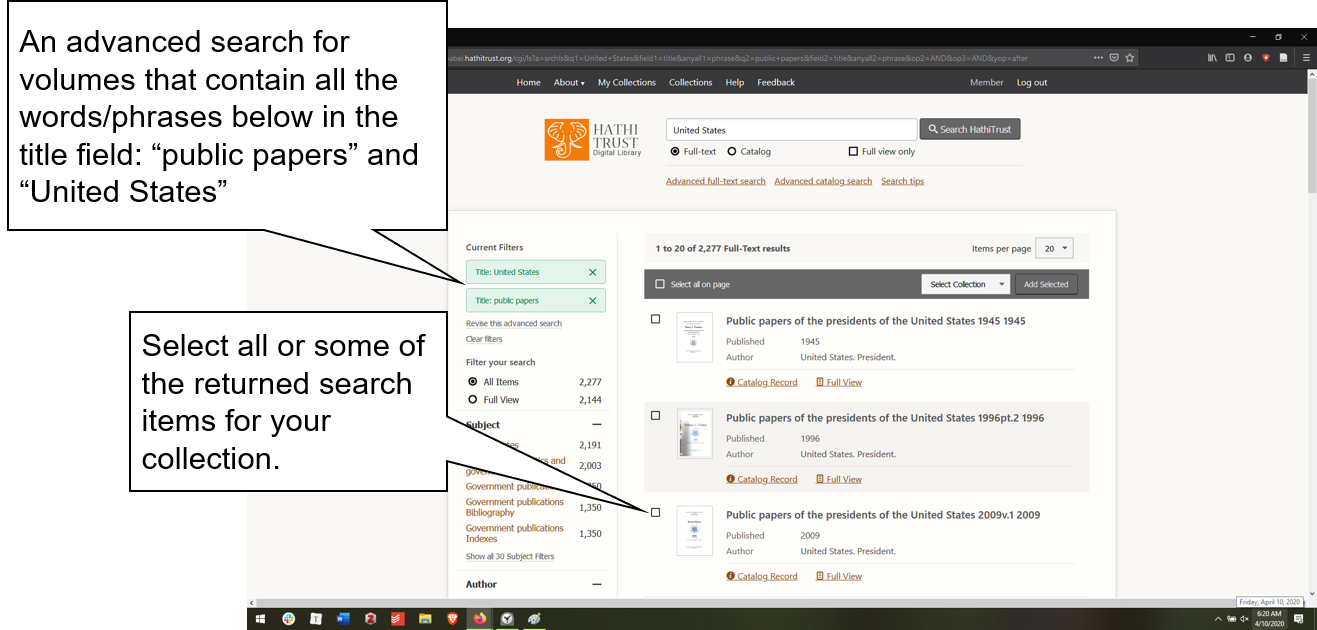
Fig 3: Search Results and Creating a collection
You can view and manage your collection at any time by clicking on the”My Collections” tab on the top of the search results page.

Fig 4: Viewing your Collection
This interface also allows you to download your collection’s metadata. This metadata includes information like the title, author, publication date, HathiTrust ID, and URL to each of the books in your collection. Downloading your metadata allows you to move your collection from the HathiTrust Digital Library to the HathiTrust Research Center, where you can perform text analysis operations.
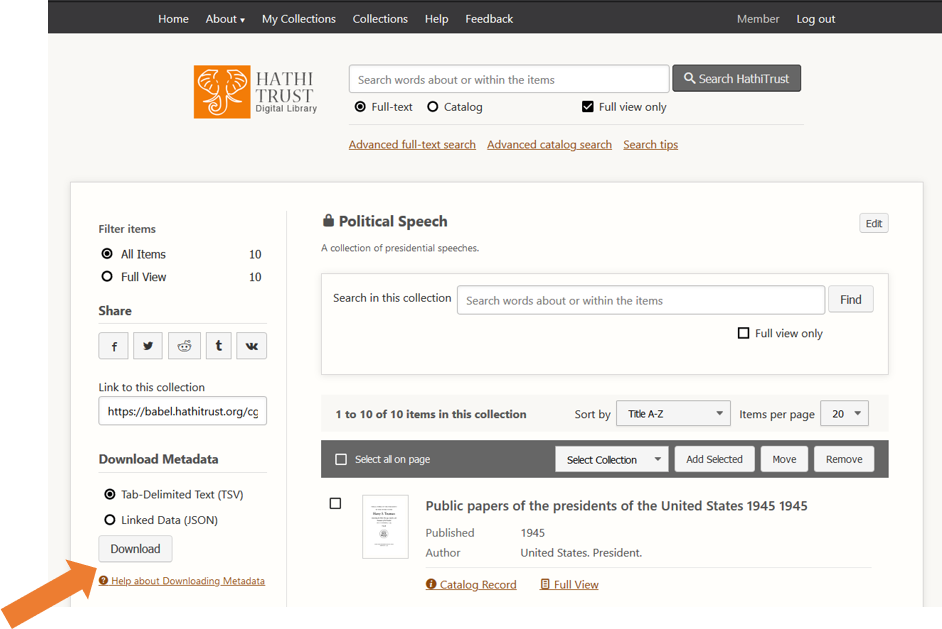
Fig 5: Downloading your Collection’s Metadata
The HathiTrust even supports bulk-adding large batches of items into a collection. It is possible to use the HathiTrust’s API to add hundreds or thousands of volumes into collections. You can glean an overview of this process in Module 4 of the slides, which I will also discuss in Part 3 of this series.
Acknowledgements
This series has been made possible from these slides, which were initially created by the HathiTrust, with subsequent edits made by Stephen Klein, Roxanne Shirazi, and Stephen Zweibel of the CUNY Graduate Center Library.

This entry is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International license.



{kind=link}