
While only some scholars in the humanities identify as digital humanists, the number of humanists who use digital tools in their work is much larger. Through the digitization of journals and archives, the spread of word processers, and the adoption of educational technologies like Blackboard, computers have found their way into our practice in many forms.

Word search in a Project Gutenberg text
One technology that could have a major effect on scholarly practice is a relatively inconspicuous one: word search. When you are trying to track down the source of a quotation, word search can be a lifesaver, and it can also provide a way of finding examples of how a particular word was used. Word search is only useful, however, if you can find searchable versions of the texts you are interested in. In this blog post, I will point out some ways you can find texts that you can search, as well as pointing out some pitfalls that you should be aware of when using automated methods to find things in texts.
Finding aids of one sort or another have been around for about as long as there have been collections of books. One venerable (and useful) type is the subject index, which has been a common addition to printed books since the early-modern period. But although word search is often used as a substitute for the index, it is in many ways closer to a concordance—in its simplest form, it presents the user with a list of every instance of a given word in a collection, without attempting to account for figurative language or circumlocution. One consequence of this rigid adherence to the words on the page is that search is highly dependent on the quality of the texts that you are using; one typo or transcription error means that a word will not show up. Because of this, it is sometimes useful to look around a little to find a better quality copy of a text.

Excerpt from an 1869 edition of Alexander Cruden’s Biblical concordance, first published in 1737
Searching individual texts
One place where you can use word search is right in your Web browser, PDF viewer, or word processor, usually using command-F on Macs or control-F on Windows. To do this, however, you need a copy of the document you want to search in a text format. If you are dealing with a text that was scanned, it might be possible to create a searchable version automatically using Optical Character Recognition (OCR). Some versions of Adobe Reader include an OCR feature, and there are many other programs available, both free (Tesseract) and commercial (Abbyy FineReader). However, OCR does not always do a good job of recognizing words, especially with older material, and it makes assumptions about language that can be problematic when applied to large collections; in particular, it tends to work best with language that follows standard orthography and follows conventional phrasing. If possible, it is better to look for a copy of a text that has been transcribed by a human being.
If you are working on a fairly well-known text that is out of copyright, a good place to look is Project Gutenberg. For this project, volunteers have transcribed over 50,000 books and made them freely available online. These editions are not always up to the standard of a scholarly edition, and there is sometimes a frustrating lack of information about provenance—the site does not always even state which edition of the book the volunteers transcribed—but if all you are trying to do is find a particular passage, they are usually sufficient.
Big databases
Another place where you can use word search is in large databases of scanned books. The most famous of these is Google Books, a project that was much publicized in the last decade and that was the occasion for an important legal ruling. Not only is Google’s collection far larger than Project Gutenberg’s, but it also includes books that are in copyright—although there are limitations on how it will allow you to view them. It doesn’t always live up to the hype with which it was announced, but it can be useful for many things.
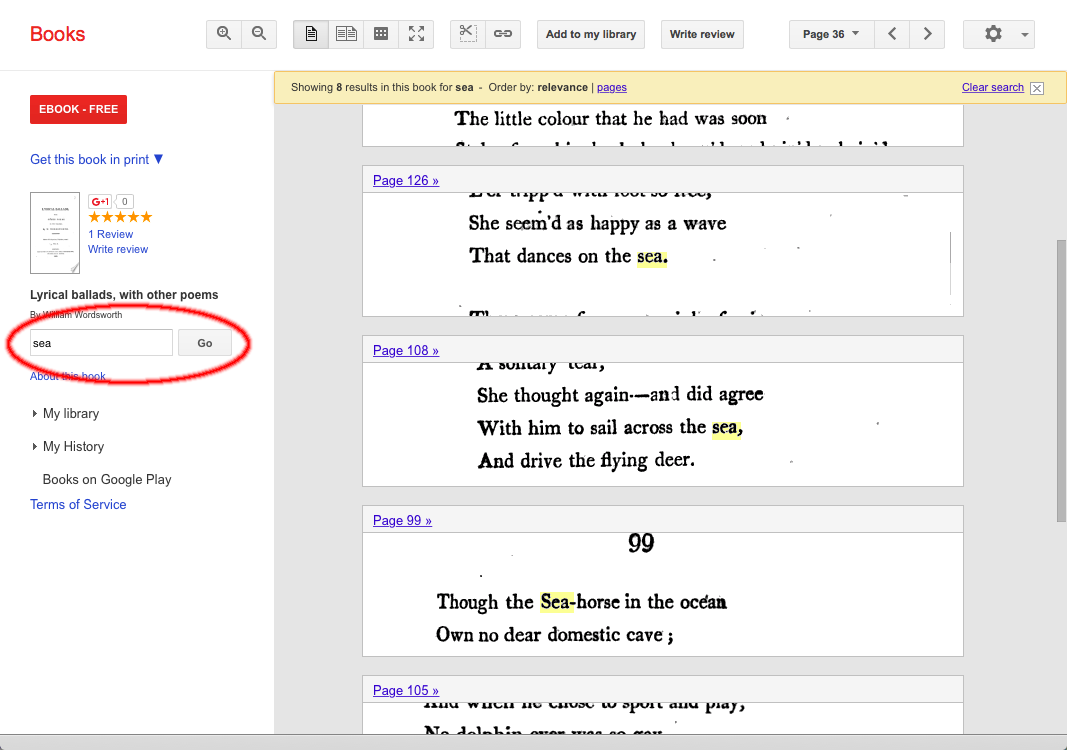
Searching within a book using Google Books
It is possible to search Google Books in two ways. First, you can use the main search engine to search Google’s entire collection, finding books that match a particular search query. Second, you can search within a particular book using the box that appears at the left of the text. The latter feature is often useful for trying to find passages you remember in books that do not have indexes—it is one reason why it can be useful to have both digital and print editions of a book.

The somewhat inconspicuous “Search tools” feature in Google Books
Although the main page of Google Books has a similar minimalist interface to the main Google page, it does include a few additional features that can be useful in scholarship. Once you get to the search results page, you will see a somewhat inconspicuous button called “Search tools”; this gives you a few ways of narrowing down your search, including an option to search within a specific range of dates, which is often very useful for historical research. Google Books also gives you some more options at the Advanced Book Search page, which allows you to search by author, title, and language, among other things.
Another database that has a large number of books is the Internet Archive (also known as Archive.org). This Web site allows you to search many of the books that were digitized by Google, along with some other books that are only available through Archive.org. It also includes huge numbers of images, audio recordings, videos, software packages, and early websites, making it one of the Internet’s most fascinating rabbit holes to get lost in.
Google Books and Archive.org do not, however, provide many options for searching, and it is often difficult to track down a particular edition of a text in these databases, even if it is in there somewhere. For many purposes, a better option—and one that not many scholars know about—is HathiTrust. This project, named after the Hindi/Urdu word for elephant, is based at the University of Indiana-Bloomington and run by a consortium of university libraries. HathiTrust’s database includes almost everything in Google Books, along with a large volume of material that was digitized by libraries specifically for the site. Unlike Google Books, it includes some periodicals and other items that are not books. Some of the texts that HathiTrust offers are only available to people with an institutional subscription, but a large portion of it is open to the public.
HathiTrust offers an advanced search feature that includes many options that Google Books doesn’t. Its bibliographic information is not always accurate, but if you bear its limitations in mind, it can be a useful go-to option when you want to cast as wide a net as possible.
The perils of OCR
While Google Books and HathiTrust can easily impress with their scale, however, in many cases you can get better results by looking at the smaller, more specialized, and—importantly—more carefully edited collections that many scholars have prepared for the Web. One of the problems with the large databases is that they are based on OCR, and the quality of their searchable versions is often quite bad. For example, this is from Archive.org’s copy of an 1820 edition of Sir Walter Scott’s Ivanhoe:

The copy that the search engine uses, however, actually looks like this:
IVAIJHOE. CHAPTER I. Once man milo the breach, dear friend*, once more, Or cloee the t*11 up with oui Bngliih dead. . I i - And jcii, good jeameD, WhoK limba were Dude in England, «bew ui here The mettle of your psiture — let ui swear Ttut jaa tte worth yon breeding. King Henry V. Cedkic, although not gi^atly confident in UU rica's message, omitted not to communicate her promise to the Black Knight and Locksley. They were well pleased to find they had a Mend with- in the place, who might, in the moment of need, be able to fadlitate their entrance, and readily agreed with the Saxon that a storm, under whaU ever disadvantages, ought to be attempted, as
Given the imperfections in automatic transcriptions, you certainly should not assume that, if nothing turns up in your search results, nothing is to be found. There will be some errors in almost any book, and, in many cases, you are more likely to find things in texts that are printed cleanly, formatted in a simple way, and typeset using a standard font. The quality, generally speaking, gets worse the further back you go, and becomes a major problem for texts printed before around 1800.
For this reason, historical research in earlier time periods is often better done using more specialized websites. Fortunately, there are numerous collections out there that are edited with much more care than large databases like Google Books, Archive.org, and HathiTrust. Next time, I will give some pointers for people looking for high-quality historical texts to use with search.
Photo by Thomas Payson, found on Wikimedia Commons.




{kind=link}
{kind=link}