Over the past couple of years, the Digital Archive Research Collective (DARC) has created resources and fostered community among digital archivists and researchers at The Graduate Center. As part of our effort to build a community of practice around digital archival work, we created a Wiki with articles on various resources for archival research, led an event series, and hosted monthly Open Meetings, inspired by the models offered by PUG, RUG, and the GIS working groups. This year, in response to the difficulty of doing archival research due to the pandemic, DARC has decided to tailor its programming according to the needs of students whose research plans have been disrupted by the inability to access archives.
While our October Open Meeting focused on streamlining communication with archivists and cultivating institutional relationships, in our second virtual Open Meeting, we explored a number of options to engage with archival data remotely, in the form of digital collections, artifacts and datasets. The generative questions of the meeting were:
- What are some possible ways to conduct research in the present moment?
- How can digital tools help us explore new possibilities to engage with archival research?
- How do we make use of dataset (and especially metadata) from archives and libraries to explore collections remotely? What kind of questions do they enable us to answer?
After a brief round of introductions, the conversation shifted organically towards two complementary approaches: first, using web APIs (software intermediaries that allows two web applications to talk to each other) to pull information from existing databases; and second, using Jupyter Notebooks to explore GLAM datasets.
Since none of the attendees (including the Digital Fellows) could claim a strong expertise in working with APIs, we referred to this tutorial on using APIs to search historical newspapers crafted by former Digital Fellow Patrick Smyth. Together, we learned about the affordances of using APIs for research purposes and explored The Metropolitan Museum of Art Collection API, applying what we learned from the tutorial. Following the documentation, we identified the base url (“https://www.metmuseum.org/”), the path (“api/collection/collectionlisting”), and the query parameter (“isHighlight”) required to visualize what the Met has flagged as “popular and important artwork” in their collections.
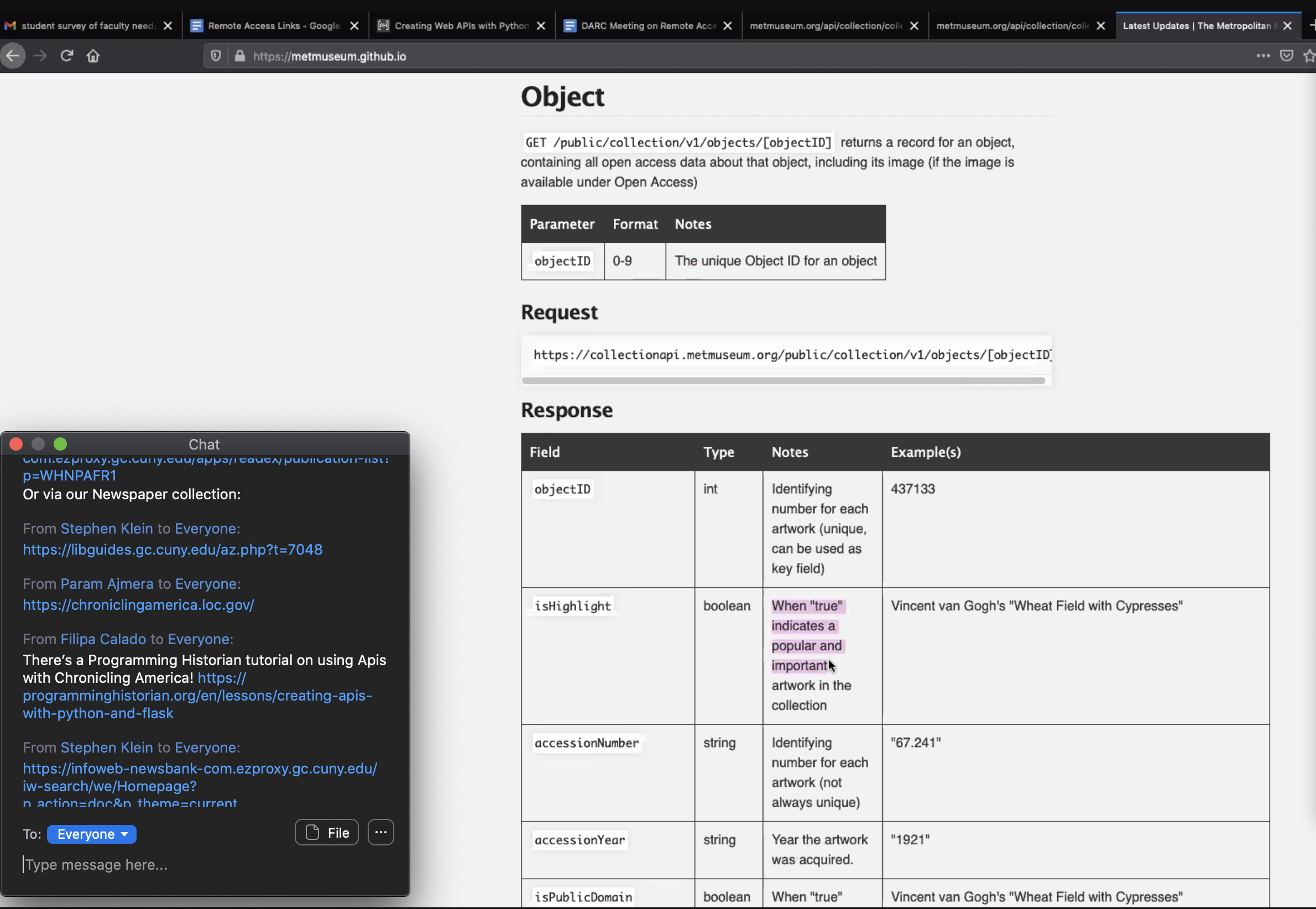
Documentation for The Metropolitan Museum of Art Collection API.
Adding those three together, we assembled the URL we would need to feed to an API to perform a query on The Met database. While we didn’t have the time to create our own API, we successfully obtained the results of the query in JSON format, a text-based data storage format designed to be easy to read for both humans and machines.
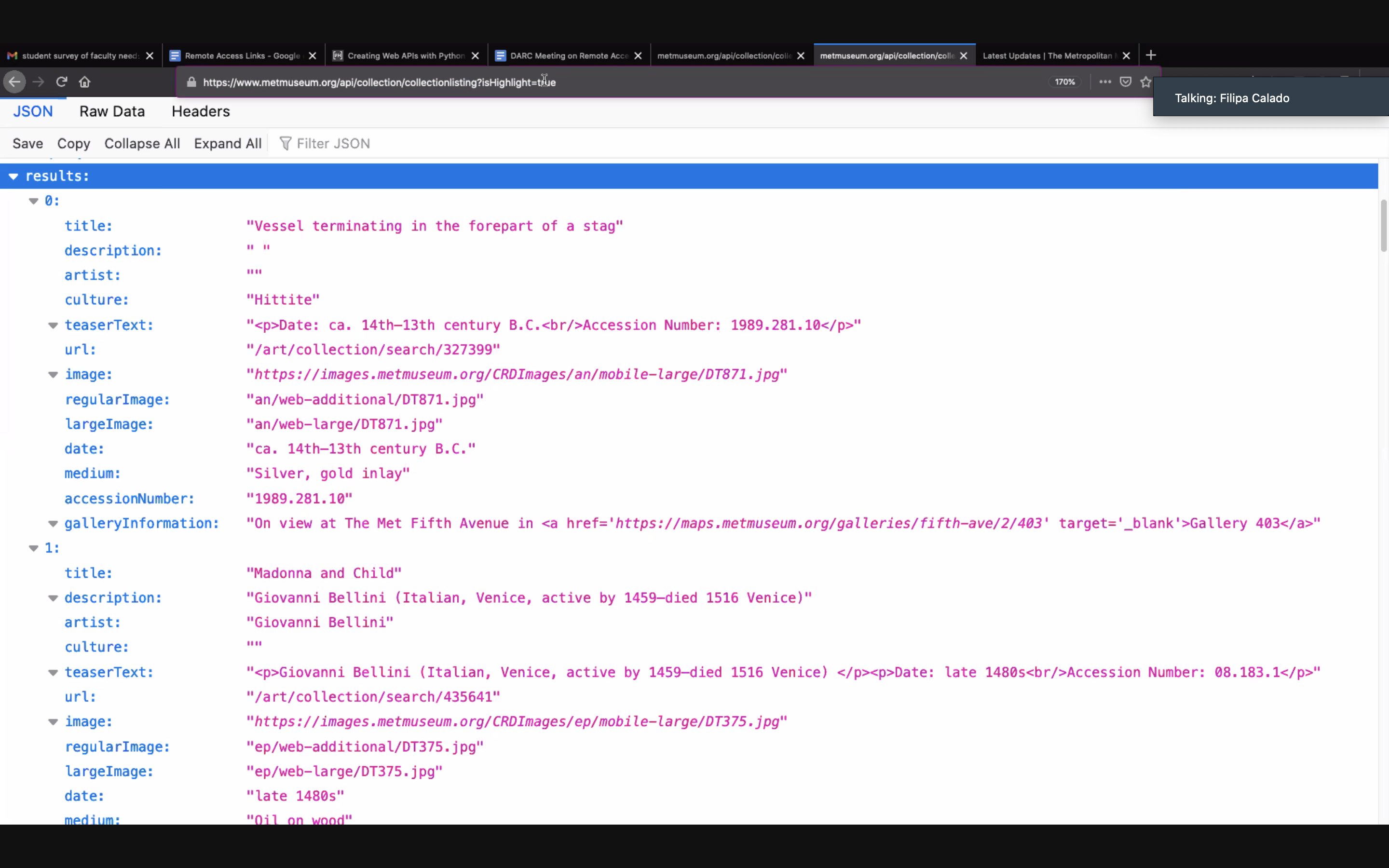
JSON Result of our Query.
We then turned to the affordances of using text analysis to study archival data. Specifically, we referred to the GLAM Workbench, a website developed by Tim Sherratt, Associate Professor of Digital Heritage at the University of Canberra, that shows how to perform queries and data analysis from a variety of GLAM collections, as well as from one’s own datasets.
GLAM data consists of collections held by cultural institutions (books, manuscripts, photographs, objects, and other artifacts) in the form of datasets. As Sherratt writes,
We’re used to exploring […] collections through online search interfaces or finding aids, but sometimes we want to do more – instead of a list of search results on a web page, we want access to the underlying collection data for analysis, enrichment, or visualisation. We want collections as data.
GLAM Workbench demonstrates a variety of tools and techniques that you can use to explore your data. The ready-made notebooks developed by Sherratt allow users to perform text analysis (and other forms of data analysis) on archival material without having to visit the archives in person, and without knowing much programming. It’s worth noting that, unlike other similar tools (such as those developed by/for JStor and HathiTrust), the notebooks on the GLAM Workbench site can also be edited by users to debug errors or adapt the applications to their needs.

Quantitative Analysis through a Jupyter Notebook on GLAM Workbench.
A still from a “How to Edit a Jupyter Notebook” on GLAM Benchwork.
GLAM data can be obtained either through APIs or by downloading datasets from an institution’s website. As we emphasized in our first meeting, using ArchiveGrid can be especially helpful to identify both digital and non-digital collections and archives, with query results often including links to finding aids and other forms of indexed datasets. Remember that whether you are looking for finding aids, more structured metadata, or information on an archive’s APIs, it’s generally a good idea to reach out to the institution, introduce yourself and your work, and ask for help from archivists.
Looking at APIs and the GLAM Workbench was especially helpful to think about the kinds of questions we can answer by looking at archival data through a mix of quantitative and qualitative methods. Through the course of the meeting, we learned new ways to conduct archival research; how digital tools can push our work in different directions than originally thought or allow us to a deeper engagement with the research questions we had already formulated; and how they can ultimately help us spend more quality time in the archives, having done some of the “dirty work” from home.
We look forward to seeing you in the next and last DARC open meeting of the semester, on Thursday, December 10, at 11am. If you’re interested in receiving updates from us or in attending future DARC meetings, don’t forget to sign up to the DARC Group on the CUNY Academic Commons! And, if there are topics you’d like us to address in future meetings, feel free to leave a message on the forum, or send us a note at gc.digitalfellows@gmail.com !

This entry is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International license.
{kind=link}