The purpose of this blog post is to introduce readers to AntConc, a freeware text analysis tool for Windows, Mac, and Linux. I discuss what this tool is and how it might be useful. I also direct readers towards more in-depth resources that explain the nuts and bolts of AntConc with greater specificity.
What is AntConc?
AntConc surfaces how words and phrases are commonly used in any given textual dataset. It is a tool that facilitates keyword-in-context searches across a collection of texts. A keyword-in-context search allows you to discern thematic and linguistic patterns in text files by presenting the keyword that you searched for, alongside other text that occurs before and after it in the document. AntConc allows for a comparative study of the ways in which language and representation might work across a number of different texts.
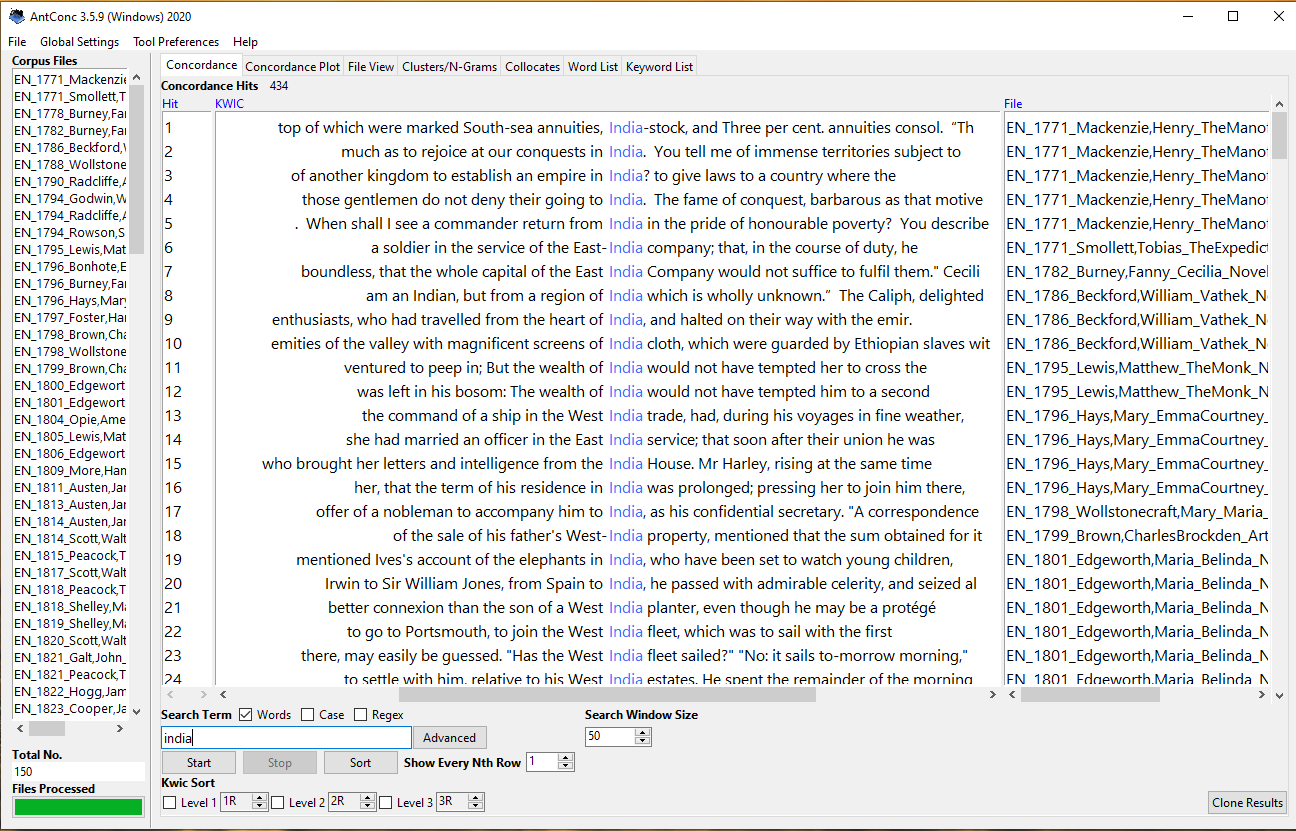
Let’s take a look at Figure 1 below to gain more information on AntConc and keyword-in-context searches. This screenshot presents the AntConc user interface, which I loaded with a dataset of 150 English novels published between 1770 and 1930. I then used AntConc to search for how the keyword “India” appears in these novels, and I specified that I would like to see 50 characters to the left and to the right of “India” in each of these texts. After a minute of processing, AntConc produced 434 results that you see below. It presents each hit for the keyword “India” in alphabetical order by file name. Moreover, we are given the 50 characters that appear to the left and to the right of “India.”
Figure 1: The AntConc Interface with a keyword in context search for “India”
Now, I can look through the results and gain a better sense of the ways in which India signifies in my dataset of novels. I might even go a step further and search for other keywords such as “Jamaica,” “Australia,” and “Canada” to see how these other English colonies were represented in my dataset. Then I can compare the differences between these different keywords to build a larger argument about colonialism, geography, representation, and English novels.
How does AntConc fit in the research process?
AntConc is a very helpful tool for digital text analysis. It is especially useful in the early stages of research when we are interested in exploring our dataset and trying to formulate a hypothesis. For example, if you have a dataset of 10,000 tweets, and you are interested in studying how gender pronouns are used, then you might consider loading the tweets into AntConc and running searches for words like “her,” “his,” “their,” etc. This would allow you to quickly scan through your dataset and gain a better understanding of how these keywords appear in your collection of tweets. Furthermore, this would also allow you to clean your dataset and get rid of the tweets that don’t contain these keywords.
Where can I learn more?
One of the major benefits of AntConc is that there many guides that people have made explaining it. I highly recommend starting with Heather Froehlich’s “Corpus Analysis with AntConc” post on Programming Historian. It provides the best in-depth look at this tool. For more visual oriented learners, I also recommend checking out the creator of AntConc’s (Laurence Anthony) 11-part YouTube video tutorial for AntConc. Those interested in a quicker guide to using AntConc might even check out the official help file to using AntConc. You can find even more guides in multiple languages on the AntConc homepage (scroll to the middle of the page).

This entry is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International license.




{kind=link}