
Working with HathiTrust Data
This post is Part 2 of a three-part series providing an introduction to the HathiTrust’s Digital Library and text analysis tools. In Part 1, I provided a brief introduction to text analysis and showed how to create collections in the HathiTrust Digital Library. In Part 2, below, I discuss how the HathiTrust Research Center’s inPho Topic Model Explorer allows us to perform a particular kind of text analysis operation. Finally in Part 3, I will discuss ways of accessing and analyzing the HathiTrust’s data at scale.
All three posts in this series are written to provide a narrative overview to these slides on Working with HathiTrust Data. I have organized these posts following the modules from the slides to allow the reader to move between the two and focus on the sections that are most interesting to them. This post is aligned with Module 3 in the slides.
The HathiTrust Digital Library preserves and provides access to over 17 million books spanning more than four centuries. It was created in 2008 by digitizing and bringing together the physical collections of a number of distinguished academic research libraries. Today, The HathiTrust Digital Library comprises over 120 partner institutions who continue to contribute to its collection. Alongside the Digital Library, the HathiTrust Research Center provides tools that facilitate text analysis on its vast corpus.
Analyzing Textual Data using the HathiTrust Research Center
In Part 1 of this series, I provided an introduction to text analysis, and discussed ways of creating collections in the HathiTrust Digital Library. In this post, we will move on to the next stage of the text analysis project, when we use algorithms to study our collection.
The HathiTrust Research Center provides a variety of tools to analyze collections. In this post we will focus on one tool in particular – the InPho Topic Model Explorer. Succinctly put, topic modeling is a text analysis method that identifies abstract “topics” that occur in a collection of texts. Topic modeling first removes frequently occuring language like “the,” “if,” “an,” and then measures the relative proximity of distinct words. It assumes that words which often occur together correspond to a shared topic. The topic model then produces an output containing lists of words drawn from the dataset, with each list pertaining to a topic.
Like every other approach to quantitative analysis, it is important to understand the processes and limitations of topic modeling. I highly recommend reading vol. 2, issue 1., of the Journal of Digital Humanities which contains a number of articles addressing the affordances and limitations of topic modeling.
To begin with topic modeling using the HathiTrust’s data, we must first go to the HathiTrust Research Center and create an account or login.

Fig 1: Logging into the HathiTrust Research Center
Then we can import our collection from The HathiTrust Digital Library and create a “workset.” A “workset” in the HathiTrust Research Center is similar to a “collection” in the HathiTrust Digital Library. They are both ways of naming and creating datasets on which algorithms can be applied.
To create a workset, click on “Worksets” in the top menu.

Fig 2: Creating a Workset, Part I
This takes you to the Worksets section of the HathiTrust Research Center, where you can view your own worksets as well as public worksets.
We then click on “Create A Workset,” which will allow us to move our collection from the HathiTrust Digital Library to the HathiTrust Research Center, or to create a workset from scratch.
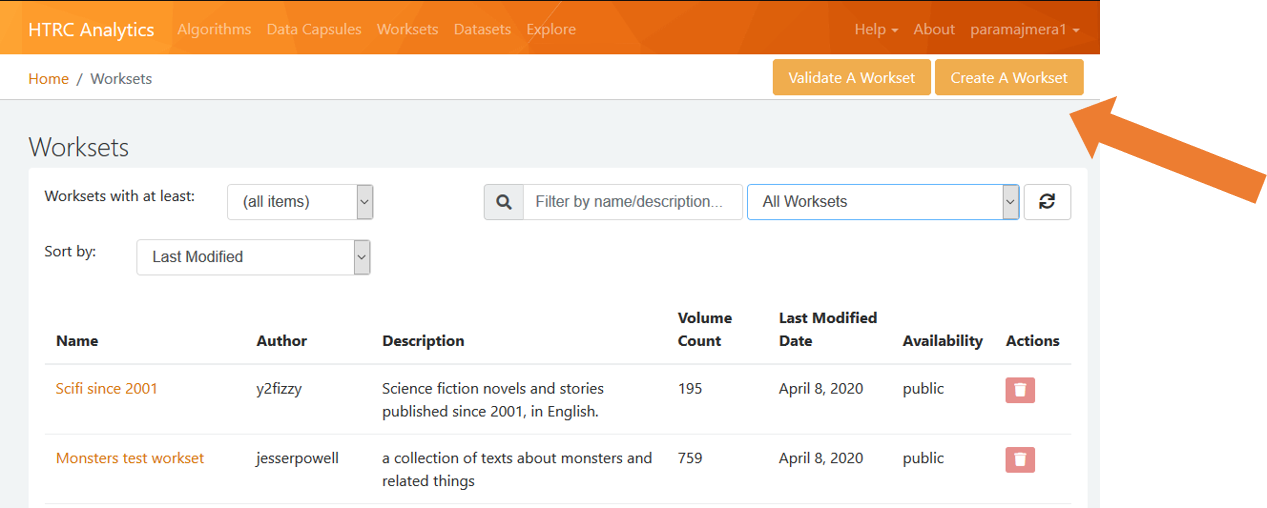
Fig 3: Creating a Workset, Part II
The HathiTrust provides many ways of moving collections from the Digital Library to the Research Center. If you are looking to run an algorithm on a collection that was created in the HathiTrust Digital Library, then I recommend going with the “upload file” option. The “import from HathiTrust” option also works, but only if your collection is publicly visible in the Digital Library. The “Import From HTRC Workset Builder” option works if you have used the Workset Builder tool to create your collection.
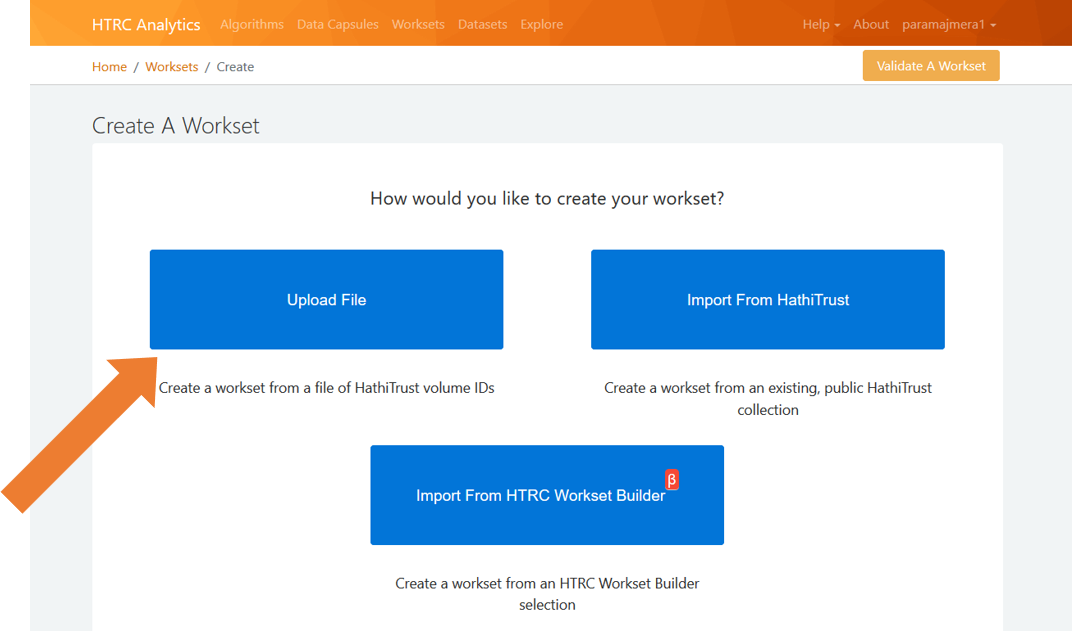
Fig 4: Uploading our Collection’s Metadata, Part I
Clicking on “upload file” takes you to another page. Here you can give your workset a name, a description, and upload the metadata file from your collection in the HathiTrust Digital Library. You can learn how to download the metadata file from your collection in part 1 of this series. Once all the information has been provided, click on the blue “Create Workset” button at the bottom of the page.
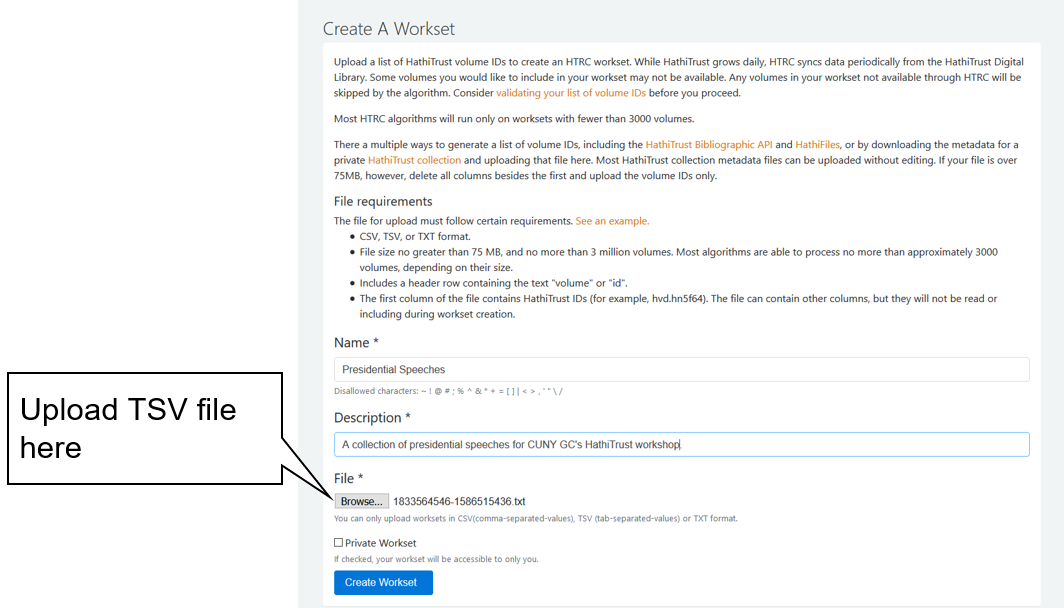
Fig 5: Uploading our Collection’s Metadata, Part II
Upon creating a workset, you should now be able to view it in the “Worksets” page.
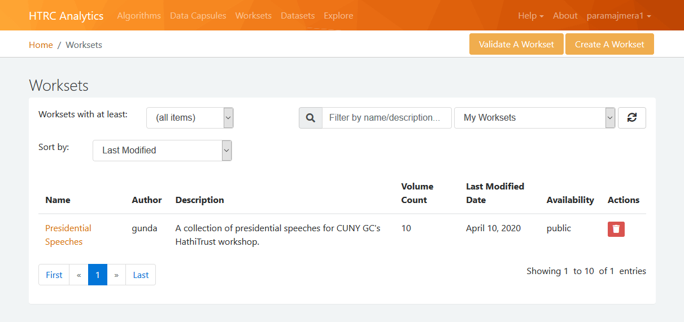
Fig 6: View your Workset
The next step to doing a topic model is to proceed to the “Algorithms” section of the HathiTrust research center, by clicking on the option in the top menu.
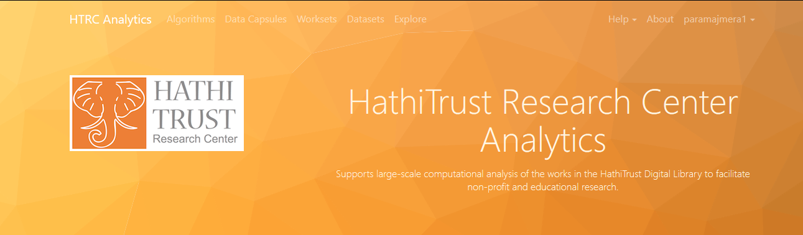
Fig 7: Proceed to Algorithms section of the HathiTrust Research Center
A number of text analysis tools are presented to us. I encourage you to explore these at your own leisure. In this post we will go with the InPho Topic Model Explorer.
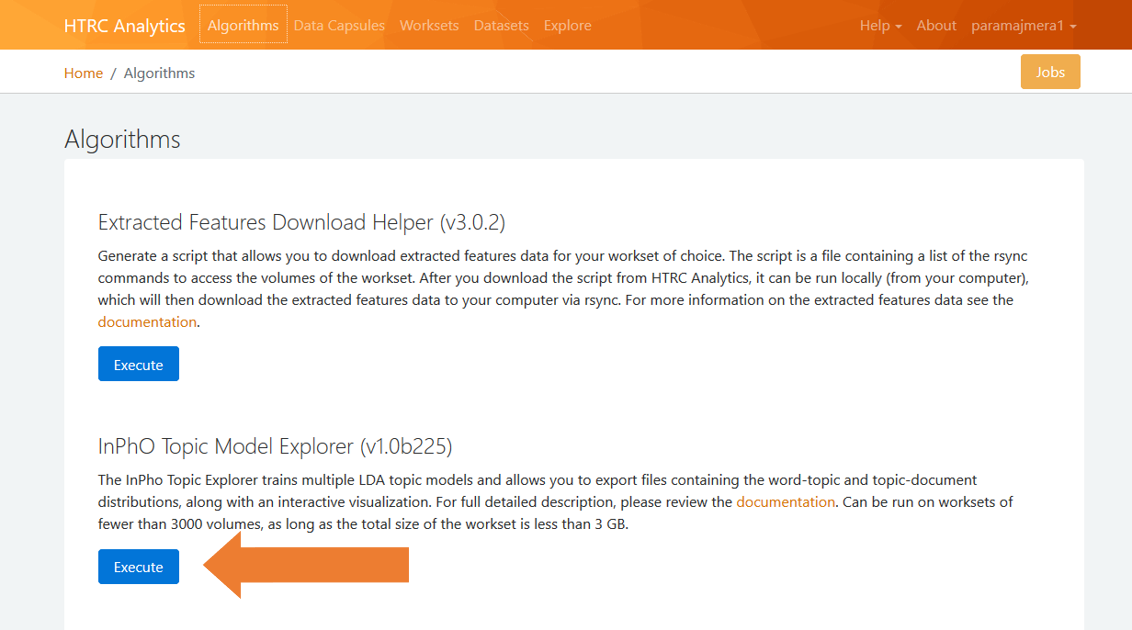
Fig 8: Executing the InPho Topic Model Explorer
The InPho Topic Model Explorer page presents an overview of its process as well as set the parameters of the algorithm. Here, we are asked to provide a job name. We are also prompted to select our workset. Next, we can adjust the parameters of our topic model by adjusting the “Number of Iterations” and “Number of Topics.”
The number of iterations determines the number of samples that topic model will use to conduct its analysis. If you increase the number of iterations, your topic model will take longer to run, but you could potentially get higher quality results. Determining the appropriate number of iterations depends on the size of your dataset and on your research questions. Are you using the topic models to find general trends in your dataset? Are you looking for outliers? These kinds of questions can help you decide on an appropriate number of iterations.
The number of topics tells the algorithm how many topics to create from your dataset. It is a way of constraining the gradation of your research. The default numbers in there tell the topic model to create a list of 20 topics, then run again and create a list of 40 topics, then run again and create 60 topics, and so on. Again, determining the appropriate number of topics depends on what you are seeking to measure and how big your dataset is.
After defining the parameters of our topic model, we can run the algorithm on our workset by clicking “submit.”
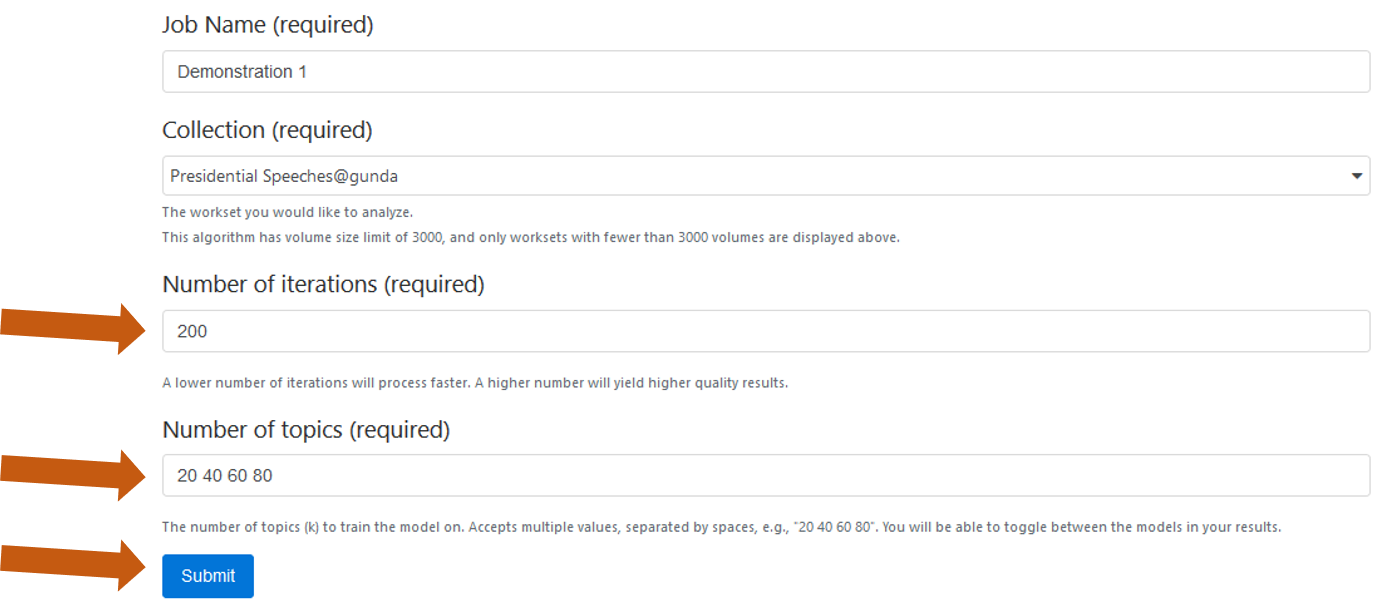
Fig 9: Defining the parameters of the topic model
Once we click “submit” and run the algorithm, it may take some time for the results to appear. When an output is ready, you will be presented with a number of ways to explore the results.
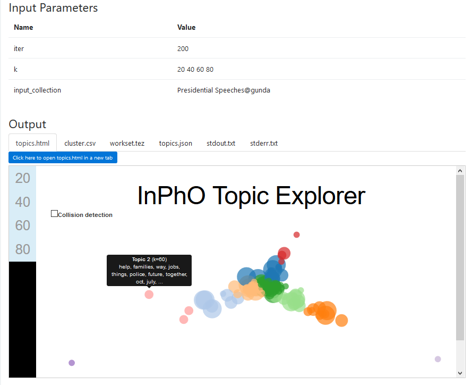
Fig 10: Topic Model Outputs
The default way in which the results are displayed are through a visualization that presents all topics as a series of variously colored bubbles. Below the visualization, the HathiTrust also provides guidelines for interpreting the visualization, where they write:
Each topic recognized by the algorithm is represented as a node (bubble). The bubble display shows the granularity of the different models and how terms may be grouped together into topical themes.
The clusters and colors are determined automatically by the algorithm, and provide only a rough guide to groups of topics that have similar themes. The different axes do not have any intrinsic meaning, but could be interpreted as representing historical or thematic dimensions in the underlying corpus.
The size of the bubbles relates to the number of topics generated (larger for fewer topics, smaller for more topics). If you trained multiple models, you can toggle to view the corresponding bubbles for each model. You have the option to turn collision detection on and off, which can improve the readability of the display.
Alongside this visualization, you can see the topics in a more readable form by clicking on the “topics.json” option. This presents a series of lists corresponding to possible topics generated by the algorithm. When I ran this topic modeling algorithm on my dataset of United States presidential speeches, I was able to generate topics based on the contents of the speeches of different presidents. These topics allowed me to identify significant themes in each of the president’s speeches, which can you see in the screenshot below.
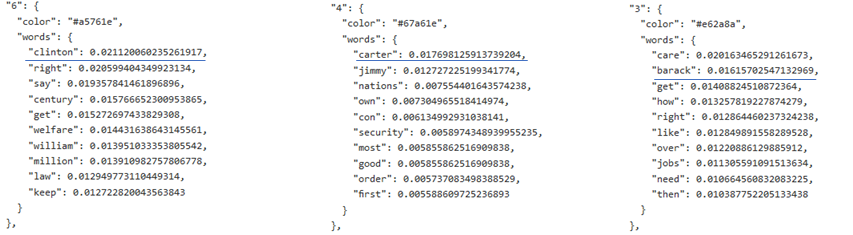
Fig 11: Topics associated with U.S. Presidents
A benefit of the InPho Topic Model Explorer is that it is easy to use and requires no deep knowledge of computer programming. Correspondingly, a drawback to this tool is that it can be a bit of a blunt instrument, and lacks the precision that other more sophisticated approaches to text analysis provides. I have found Topic Modeling to be an effective way of conducting exploratory research on large datasets whose contents are largely unfamiliar to the researcher. Topic Modeling is a helpful way of generating preliminary categories to help organize the dataset, and it is useful in finding significant trends as well as outliers in the data.
Acknowledgements
This post was made possible from these slides, which were initially created by the HathiTrust, with subsequent edits made by Stephen Klein, Roxanne Shirazi, and Stephen Zweibel of the CUNY Graduate Center Library.

This entry is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International license.



{kind=link}